编程模式
模式类别
使用 MPI 时有两种最基本的并行程序设计模式,即对等模式和主从模式(master-salve)。在对等模式中,每个进程的功能和代码基本一致,只是处理的数据和对象有所不同。而主从模式中,会有一个 master 线程,用来管理其他的线程(称为 workers 或者 slaves)。
对等模式
单独发送接收
这里我们使用 MPI 并行程序设计 书中的例子 -- Jacobi 迭代来展示对等模式。下面是根据书上的代码修改后的原始代码。从下面的代码可以看出,Jacobi 迭代得到的新值其实就是原来旧值点相邻数值点的平均数。这里为了简单,我们忽略了第一行、第一列、最后一行和最后一列值的计算,而只是使用它们的初始值。还有一点,在每次 k 迭代时,a 更新后的值会首先保存到数组 b 中,等到 a 的值全部计算出来之后,再将 a 的值更新,这样在进行 i 迭代和 j 迭代时,迭代之间就没有数据依赖关系,可以并行。 如果将 b[i][j] = 0.25 * ... 修改为 a[i][j] = 0.25 * ...,这样在进行 i 迭代和 j 迭代时,每次迭代都会依赖前一次的计算结果,是很难并行的。
// 迭代10次,计算时忽略了 0,n-1 行 和 0,n-1 列
for (k = 0; k < 1; k++) {
for (i = 1; i < n - 1; i++) {
for (j = 1; j < m - 1; j++) {
b[i][j] = 0.25 * (a[i - 1][j] + a[i + 1][j] + a[i][j + 1] + a[i][j - 1]);
}
}
for (i = 1; i < m - 1; i++) {
for (j = 1; j < n - 1; j++) {
a[i][j] = b[i][j];
}
}
}
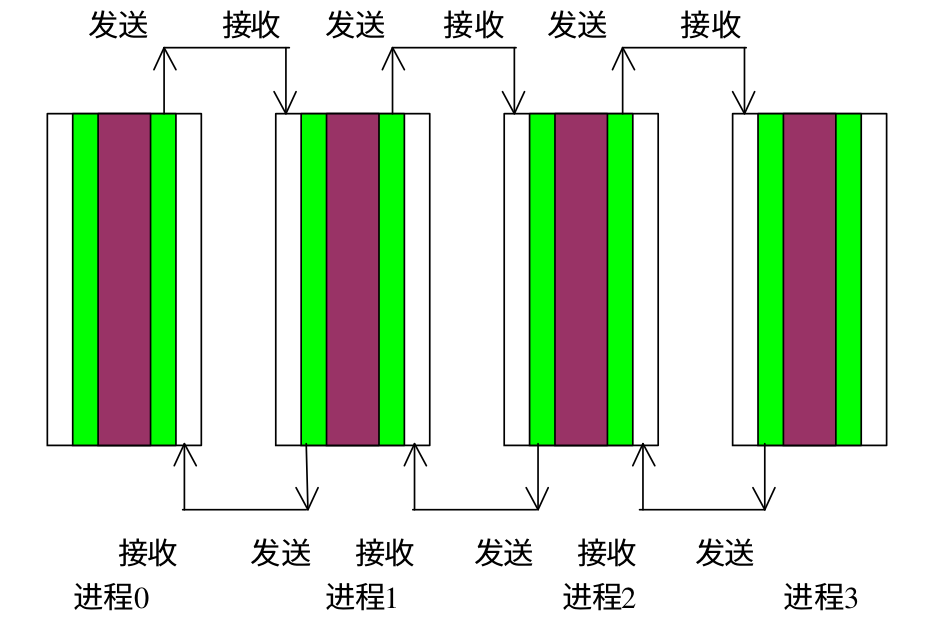
对于上面的代码,并行策略十分简单,假设有 n 个进程,m 行数据,每个进程计算 m / n 行数据即可。 假设有 4 个进程,8行数据(去掉第一行和最后一行),那么进程 0 计算 1 和 2 行数据,进程 1 计算 3 和 4 行数据,以此类推。进程在每次 k 迭代时,除了之后自己计算行的数据,还需要知道相邻行的数据。以进程 1 为例,在 i 迭代开始之前,除了需要知道第 3 行和第 4 行的数据,还需要知道第 2 行和第 5 行的数据,这两行数据分别由进程 0 和进程 2 计算,需要在 i 迭代开始之前,由进程 0 和 进程 2 传递过来,同时进程 1 的第 3 行数据需要传给进程 0, 第 4 行数据数据需要传给进程 2 。下面是一张示意图,原文中是按列计算,和按行计算原理一样。
下面是代码实现
void mpi_jacobi() {
int m = 10;
int n = 10;
int a[m][n];
int b[m][n];
int i, j, k;
for(i = 0; i < m; i++) {
for(j = 0; j < n; j++) {
a[i][j] = rand() / (RAND_MAX + 1.0) * 10 * (i + j) ;
}
}
int size, rank;
MPI_Status status;
MPI_Init(NULL, NULL);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// 每个进程计算的行数,为了简单这里假设正好可以除尽
int gap = (m - 2) / size;
int start = gap * rank + 1;
int end = gap * (rank + 1);
// 迭代10次,计算时忽略了 0,n-1 行 和 0,n-1 列
for(k = 0; k < 10; k++) {
// 从右侧邻居获得数据
if(rank < size - 1) {
MPI_Recv(&a[end+1][0], n, MPI_INT, rank + 1, 100, MPI_COMM_WORLD, &status);
}
// 向左侧邻居发送数据
if(rank > 0) {
MPI_Send(&a[start][0], n, MPI_INT, rank - 1, 100, MPI_COMM_WORLD);
}
// 向右侧邻居发送数据
if(rank < size - 1) {
MPI_Send(&a[end][0], n, MPI_INT, rank + 1, 99, MPI_COMM_WORLD);
}
// 从左侧邻居获得数据
if(rank > 0 ) {
MPI_Recv(&a[start - 1][0], n, MPI_INT, rank - 1, 99, MPI_COMM_WORLD, &status);
}
for(i = start; i <= end; i++) {
for(j = 1; j < m -1; j++) {
b[i][j] = 0.25 * (a[i-1][j] + a[i+1][j] + a[i][j+1] + a[i][j-1]);
}
}
for(i = start; i <= end; i++) {
for(j = 1; j < n - 1; j++) {
a[i][j] = b[i][j];
}
}
}
// 这里按照顺序输出结果
for(k = 0; k< size; k++) {
MPI_Barrier(MPI_COMM_WORLD);
if(rank == k) {
for(i = start; i <= end; i++) {
for(j = 1; j < n-1; j++) {
printf("a[%d][%d] is %-4d ", i, j, a[i][j]);
}
printf("\n");
}
}
}
MPI_Finalize();
}
同时发送接受
通过使用 MPI_Sendrecv 函数,我们可以实现同时向其他进程发送数据以及从其他进程接受数据,下面是函数原型:
MPI_Sendrecv(
void *sendbuf, // 发送缓冲区的起始地址
int sendcount, // 发送数据的个数
MPI_Datatype sendtype, // 发送数据的数据类型
int dest, // 目标进程
int sendtag, // 发送消息标识
void *recvbuf, // 接收缓冲区的初始地址
int recvcount, // 最大接受数据个数
MPI_Datatype recvtype, // 接受数据类型
int source, // 源进程标识
int recvtag, // 接受消息标识
MPI_Comm comm, // 通信域
MPI_Status *status // 返回状态
)
MPI_Sendrecv 可以接收 MPI_Send 的消息, MPI_Recv 也可以接收 MPI_Sendrecv 的消息。
除了 MPI_Sendrecv,我们还可以使用 MPI_Sendrecv_replace 来同时发送和接受。下面是函数原型:
MPI_Sendrecv_replace(
void * buf, // 发送和接收缓冲区的起始地址
int count, // 发送和接收缓冲区中的数据个数
MPI_Datatype datatype, // 缓冲区中的数据类型
int dest, // 目标进程标识
int sendtag, // 发送信息标识
int source, // 源进程标识
int recvtag, // 接收消息标识
MPI_Comm comm, // 通信域
MPI_Status status // 返回状态
)
MPI_Sendrecv_replace 函数会首先将缓冲区的数据发送出去,然后再将接受的数据放到缓冲区里。
下面是代码示例:
void mpi_jacobi2() {
int m = 10;
int n = 10;
int a[m][n];
int b[m][n];
int i, j, k;
for(i = 0; i < m; i++) {
for(j = 0; j < n; j++) {
a[i][j] = rand() / (RAND_MAX + 1.0) * 10 * (i + j) ;
}
}
int size, rank;
MPI_Status status;
MPI_Init(NULL, NULL);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// 每个进程计算的行数,为了简单这里假设正好可以除尽
int gap = (m - 2) / size;
int start = gap * rank + 1;
int end = gap * (rank + 1);
// 迭代10次,计算时忽略了 0,n-1 行 和 0,n-1 列
for(k = 0; k < 3; k++) {
// 向右侧邻居发送数据并且从右侧邻居获得数据
if(rank < size - 1) {
MPI_Sendrecv(&a[end][0], n, MPI_INT, rank + 1, 100, &a[end+1][0], n, MPI_INT, rank + 1, 100, MPI_COMM_WORLD, &status);
}
// 向左侧邻居发送数据并且从左侧邻居接受数据
if(rank > 0) {
MPI_Sendrecv(&a[start][0], n, MPI_INT, rank - 1, 100, &a[start - 1][0], n, MPI_INT, rank - 1, 100, MPI_COMM_WORLD, &status);
}
for(i = start; i <= end; i++) {
for(j = 1; j < m -1; j++) {
b[i][j] = 0.25 * (a[i-1][j] + a[i+1][j] + a[i][j+1] + a[i][j-1]);
}
}
for(i = start; i <= end; i++) {
for(j = 1; j < n - 1; j++) {
a[i][j] = b[i][j];
}
}
}
// 这里按照顺序输出结果
for(k = 0; k< size; k++) {
MPI_Barrier(MPI_COMM_WORLD);
if(rank == k) {
for(i = start; i <= end; i++) {
for(j = 1; j < n-1; j++) {
printf("a[%d][%d] is %-4d ", i, j, a[i][j]);
}
printf("\n");
}
}
}
MPI_Finalize();
}
使用虚拟进程
虚拟进程(MPI_PROC_NULL)是不存在的假想进程。在 MPI 中的主要作用是充当真是进程通信的目标或者源。使用虚拟进程可以大大简化处理边界的代码,使程序更加清晰。一个真实进程向虚拟进程 MPI_PROC_NULL 发送消息会立即成功返回,一个真实进程从虚拟进程 MPI_PROC_NULL 接收消息也会立即返回。下面是示例
void mpi_jacobi3() {
int m = 10;
int n = 10;
int a[m][n];
int b[m][n];
int i, j, k;
for(i = 0; i < m; i++) {
for(j = 0; j < n; j++) {
a[i][j] = rand() / (RAND_MAX + 1.0) * 10 * (i + j) ;
}
}
int size, rank;
MPI_Status status;
MPI_Init(NULL, NULL);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// 每个进程计算的行数,为了简单这里假设正好可以除尽
int gap = (m - 2) / size;
int dist_pro = 0;
int start = gap * rank + 1;
int end = gap * (rank + 1);
// 迭代10次,计算时忽略了 0,n-1 行 和 0,n-1 列
for(k = 0; k < 3; k++) {
dist_pro = rank + 1;
if(dist_pro > size - 1) {
dist_pro = MPI_PROC_NULL;
}
// 向右侧邻居发送数据并且从右侧邻居获得数据
MPI_Sendrecv(&a[end][0], n, MPI_INT, dist_pro, 100, &a[end+1][0], n, MPI_INT, dist_pro, 100, MPI_COMM_WORLD, &status);
dist_pro = rank - 1;
if(dist_pro < 0) {
dist_pro = MPI_PROC_NULL;
}
// 向左侧邻居发送数据并且从左侧邻居接受数据
MPI_Sendrecv(&a[start][0], n, MPI_INT, dist_pro, 100, &a[start - 1][0], n, MPI_INT, dist_pro, 100, MPI_COMM_WORLD, &status);
for(i = start; i <= end; i++) {
for(j = 1; j < m -1; j++) {
b[i][j] = 0.25 * (a[i-1][j] + a[i+1][j] + a[i][j+1] + a[i][j-1]);
}
}
for(i = start; i <= end; i++) {
for(j = 1; j < n - 1; j++) {
a[i][j] = b[i][j];
}
}
}
// 这里按照顺序输出结果
for(k = 0; k< size; k++) {
MPI_Barrier(MPI_COMM_WORLD);
if(rank == k) {
for(i = start; i <= end; i++) {
for(j = 1; j < n-1; j++) {
printf("a[%d][%d] is %-4d ", i, j, a[i][j]);
}
printf("\n");
}
}
}
MPI_Finalize();
}
主从模式
矩阵向量乘
在矩阵向量乘中,首先主进程将向量 B 广播给所有的从进程,然后将矩阵 A 的各行依次发送给从进程,从进程计算一行和 B 相乘的结果,然后将结果返回给主线程。为了简单我们使用下面的矩阵,程序中一共 4 个进程,除去一个主进程,其余进程正好处理一行 A 矩阵。 下面是矩阵乘的原始代码
void matrix() {
int n = 3;
int a[n][n];
int b[n][1];
int c[n][1];
int i, j;
for(i = 0; i < n; i++) {
b[i][0] = 2;
c[i][0] = 0;
for(j = 0; j < n; j++) {
a[i][j] = i + j;
}
}
for(i = 0; i < n; i++) {
for(j = 0; j < n; j++) {
c[i][0] += a[i][j] * b[i][0];
}
}
for(i = 0; i < n; i++) {
for(j = 0; j < n; j++) {
printf("a[%d][%d] is %-4d ", i,j, a[i][j]);
}
printf("\n");
}
printf("\n");
for(i = 0; i < n; i++) {
printf("b[%d] id %d\n", i, b[i][0]);
}
printf("\n");
for(i = 0; i < n; i++) {
printf("c[%d] id %d\n", i, c[i][0]);
}
}
在修改之前,我们首先介绍一个函数 MPI_Bcast,MPI_Bcast 可以将数据广播给其他进程,下面是函数原型
MPI_Bcast(
void* data, // 缓冲区的起始地址
int count, // 数据的个数
MPI_Datatype datatype, // 数据类型
int root, // 广播数据的根进程标识
MPI_Comm communicator // 通信域
)
MPI_Bcast 的实现类似于下面的代码,不过 MPI 的实现进行了优化,使广播更加高效。
void my_bcast(void* data, int count, MPI_Datatype datatype, int root,
MPI_Comm communicator) {
int world_rank;
MPI_Comm_rank(communicator, &world_rank);
int world_size;
MPI_Comm_size(communicator, &world_size);
if (world_rank == root) {
// If we are the root process, send our data to everyone
int i;
for (i = 0; i < world_size; i++) {
if (i != world_rank) {
MPI_Send(data, count, datatype, i, 0, communicator);
}
}
} else {
// If we are a receiver process, receive the data from the root
MPI_Recv(data, count, datatype, root, 0, communicator,
MPI_STATUS_IGNORE);
}
}
在使用 MPI_Bcast 的时候,我们要注意不需要使用 MPI_Recv 接受,而是在每个进程里都调用 MPI_Bcast,下面是使用 MPI 实现向量乘的一个简单示例:
void mpi_matrix() {
int n = 3;
int a[n][n];
int b[n][1];
int c[n][1];
int i, j;
int rank, size;
MPI_Status status;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if(rank == 0) {
// 在主进程进行初始化
for(i = 0; i < n; i++) {
b[i][0] = 2;
c[i][0] = 0;
for(j = 0; j < n; j++) {
a[i][j] = i + j;
}
}
// 将 B 数组广播给其他进程
MPI_Bcast(b, n, MPI_INT, 0, MPI_COMM_WORLD);
// 为每个进程分配一行 a 数组的数据
for(i = 0; i < n; i++) {
MPI_Send(&a[i][0], n, MPI_INT, i + 1, 99, MPI_COMM_WORLD);
}
// 接收每个进程的计算结果
for(i = 0; i < n; i++) {
MPI_Recv(&c[i], 1, MPI_INT, i + 1, 99, MPI_COMM_WORLD, &status);
}
for(i = 0; i < n; i++) {
printf("c[%d] id %d\n", i, c[i][0]);
}
} else {
// 接受广播数据
MPI_Bcast(b, n, MPI_INT, 0, MPI_COMM_WORLD);
// 接受 a 的数据,这里将数据存放在 a[0][0] - a[0][3] 中
MPI_Recv(a, n, MPI_INT, 0, 99, MPI_COMM_WORLD, &status);
c[rank-1][0] = 0;
for(i = 0; i < n; i++) {
c[rank-1][0] += a[0][i] * b[i][0];
}
MPI_Send(&c[rank-1][0], 1, MPI_INT, 0, 99, MPI_COMM_WORLD);
}
}