组通信
前面提到的通信都是点到点通信,这里介绍组通信。MPI 组通信和点到点通信的一个重要区别就在于它需要一个特定组内的所有进程同时参加通信,而不是像点对点通信那样只涉及到发送方和接收方两个进程。组通信在各个进程中的调用方式完全相同,而不是像点对点通信那样在形式上有发送和接收的区别。
功能
组通信一般实现三个功能:
- 通信:主要完成组内数据的传输
- 同步:实现组内所有进程在特定点的执行速度保持一致
- 计算:对给定的数据完成一定的操作
消息通信
对于组通信来说,按照通信方向的不同,可以分为以下三种:一对多通信,多对一通信和多对多通信,下面是这三类通信的示意图:
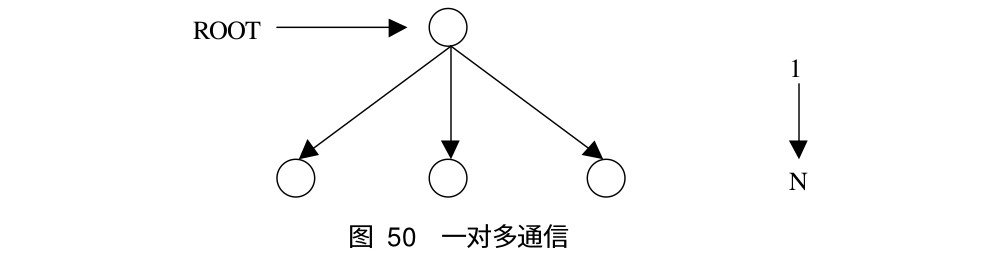
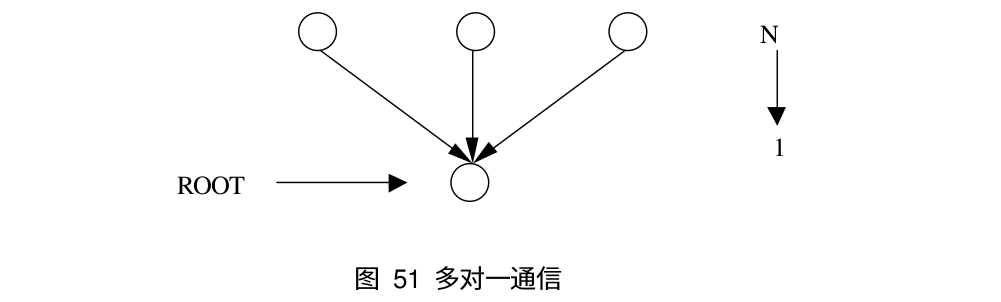
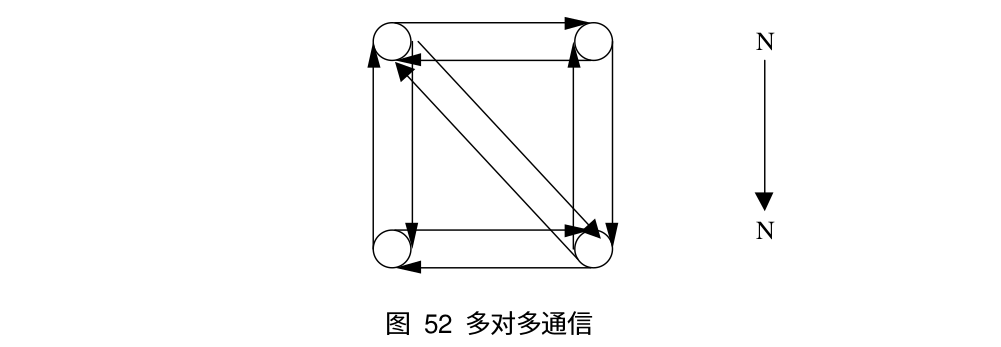
同步
组通信提供了专门的调用以完成各个进程之间的同步,从而协调各个进程的进度和步伐。下面是 MPI 同步调用的示意图
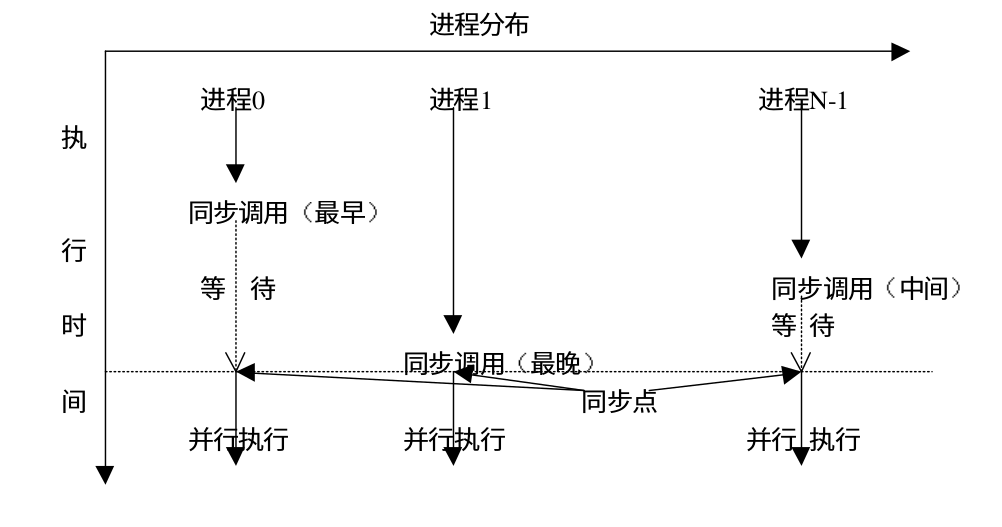
计算功能
MPI 组通信提供了计算功能的调用,通过这些调用可以对接收到的数据进行处理。当消息传递完毕后,组通信会用给定的计算操作对接收到的数据进行处理,处理完毕后将结果放入指定的接收缓冲区。
通信
广播
MPI_Bcast 是一对多通信的典型例子,它可以将 root 进程中的一条信息广播到组内的其它进程,同时包括它自身。在执行调用时,组内所有进程(不管是 root 进程还是其它的进程)都使用同一个通信域 comm 和根标识 root,其执行结果是将根进程消息缓冲区的消息拷贝到其他的进程中去。下面是 MPI_Bcast 的函数原型:
int MPI_Bcast(
void * buffer, // 通信消息缓冲区的起始位置
int count, // 广播 / 接收数据的个数
MPI_Datatype datatype, // 广播 / 接收数据的数据类型
int root, // 广播数据的根进程号
MPI_Comm comm // 通信域
);
对于广播调用,不论是广播消息的根进程,还是从根接收消息的其他进程,在调用形式上完全一致,即指明相同的根,相同的元素个数以及相同的数据类型。下面是广播前后各进程缓冲区中数据的变化
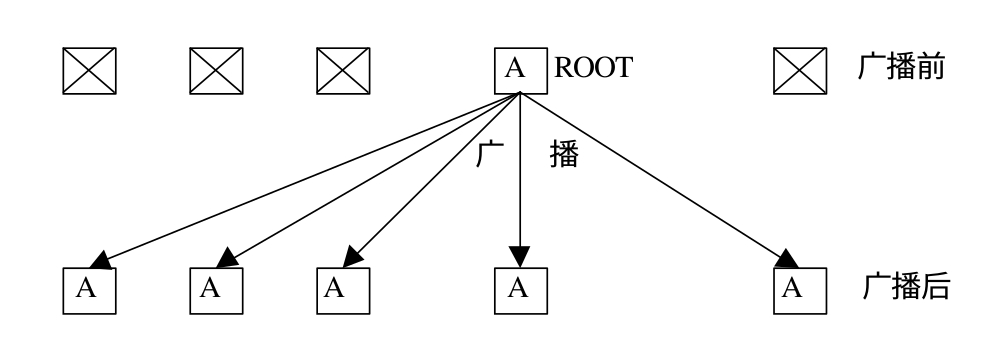
MPI_Bcast 的实现类似于下面的代码,不过 MPI 的实现进行了优化,使广播更加高效。
void my_bcast(void* data, int count, MPI_Datatype datatype, int root,
MPI_Comm communicator) {
int world_rank;
MPI_Comm_rank(communicator, &world_rank);
int world_size;
MPI_Comm_size(communicator, &world_size);
if (world_rank == root) {
// If we are the root process, send our data to everyone
int i;
for (i = 0; i < world_size; i++) {
if (i != world_rank) {
MPI_Send(data, count, datatype, i, 0, communicator);
}
}
} else {
// If we are a receiver process, receive the data from the root
MPI_Recv(data, count, datatype, root, 0, communicator,
MPI_STATUS_IGNORE);
}
}
下面是使用 MPI 广播的一个例子,进程 0 初始化数据,同时广播到其他进程
#include <stdio.h>
#include <stdlib.h>
#include "mpi.h"
int main() {
int rank;
int value;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank == 0) {
value = 10;
}
// 将进程 0 的数据广播到其他进程中
MPI_Bcast(&value, 1, MPI_INT, 0, MPI_COMM_WORLD);
printf("Process %d value is %d\n", rank, value);
MPI_Finalize();
}
收集
通过 MPI_Gather 可以将其他进程中的数据收集到根进程。根进程接收这些消息,并把它们按照进程号 rank 的顺序进行存储。对于所有非根进程,接收缓冲区会被忽略,但是各个进程仍需提供这一参数。在 gather 调用中,发送数据的个数 sendcount 和发送数据的类型 sendtype 接收数据的个数 recvcount 和接受数据的类型 recvtype 要完全相同。下面是 MPI_Gather 的函数原型
int MPI_Gather(
void * sendbuf, // 发送缓冲区的起始地址
int sendcount, // 发送数据的个数
MPI_Datatype sendtype, // 发送数据类型
void * recvbuf, // 接收缓冲区的起始地址
int recvcount, // 接收数据的个数
MPI_Datatype recvtype, // 接收数据的类型
int root, // 根进程的编号
MPI_Comm comm // 通信域
);
下面是 gather 的示意图:
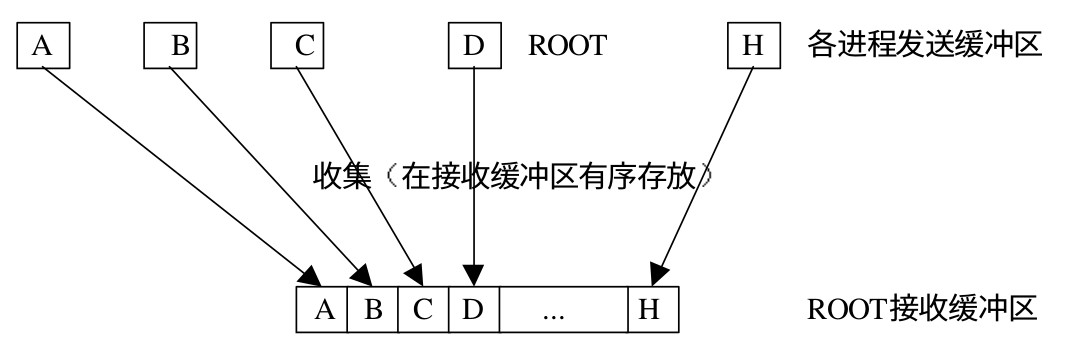
MPI_Gatherv 和 MPI_Gather 类似,也可以完成数据收集的功能,但是它可以从不同的进程接受不同数量的数据。进程接收元素的个数 recvcounts 是一个数组,用来指定从不同进程接受的数据元素的个数 。跟从每一个进程接收的数据元素个数可以不同,但是需要注意的是发送和接受的个数需要保持一致。另外 MPI_Gatherv 还提供一个位置偏移数组 displs,用户指定接收的数据在消息缓冲区中的索引,下面是 MPI_Gatherv 的函数原型:
int MPI_Gatherv(
void * sendbuf, // 发送缓冲区的起始地址
int sendcount, // 发送数据的个数
MPI_Datatype sendtype, // 发送数据类型
void * recvbuf, // 接收缓冲区的起始地址
int * recvcounts, // 从每个进程接收的数据个数
int * displs, // 接收数据在消息缓冲区中的索引
MPI_Datatype recvtype, // 接收数据的类型
int root, // 根进程的编号
MPI_Comm comm // 通信域
);
下面是使用 MPI_Gather 的一个示例:
void gather() {
int size;
int rank;
int n = 10;
int send_array[n];
int * recv_array;
int i;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 初始化其它进程的数据
for(i = 0; i < n; i++) {
send_array[i] = i + rank * n;
}
if(rank == 0) {
recv_array = (int *)malloc(sizeof(int) * n * size);
}
MPI_Gather(send_array, n, MPI_INT, recv_array, n, MPI_INT, 0, MPI_COMM_WORLD);
if(rank == 0) {
for(i = 0; i < n * size; i++) {
printf("recv_array[%d] id %d\n", i, recv_array[i]);
}
free(recv_array);
}
MPI_Finalize();
}
下面是使用 MPI_Gatherv 的一个示例
void gatherv() {
int size;
int rank;
int n = 10;
int send_array[n];
int * recv_array;
int i;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int recv_count[size];
int displs[size];
for(i = 0; i < size; i++) {
recv_count[i] = i + 1;
displs[i] = 10 * i;
}
// 初始化其它进程的数据
for(i = 0; i < n; i++) {
send_array[i] = i + rank * n;
}
if(rank == 0) {
recv_array = (int *)malloc(sizeof(int) * n * size);
}
MPI_Gatherv(send_array, recv_count[rank], MPI_INT, recv_array, recv_count, displs, MPI_INT, 0, MPI_COMM_WORLD);
if(rank == 0) {
for(i = 0; i < n * size; i++) {
printf("recv_array[%d] id %d\n", i, recv_array[i]);
}
free(recv_array);
}
MPI_Finalize();
}
散发
MPI_Scatter 是一对多的组通信调用,和广播不同的是,root 进程向各个进程发送的数据可以是不同的。MPI_Scatter 和 MPI_Gather 的效果正好相反,两者互为逆操作。下面是 MPI_Scatter 的函数原型
int MPI_scatter(
void * sendbuf, // 发送缓冲区的起始地址
int sendcount, // 发送数据的个数
MPI_Datatype sendtype, // 发送数据类型
void * recvbuf, // 接收缓冲区的起始地址
int recvcount, // 接收数据的个数
MPI_Datatype recvtype, // 接收数据的类型
int root, // 根进程的编号
MPI_Comm comm // 通信域
);
下面是 scatter 的示意图:
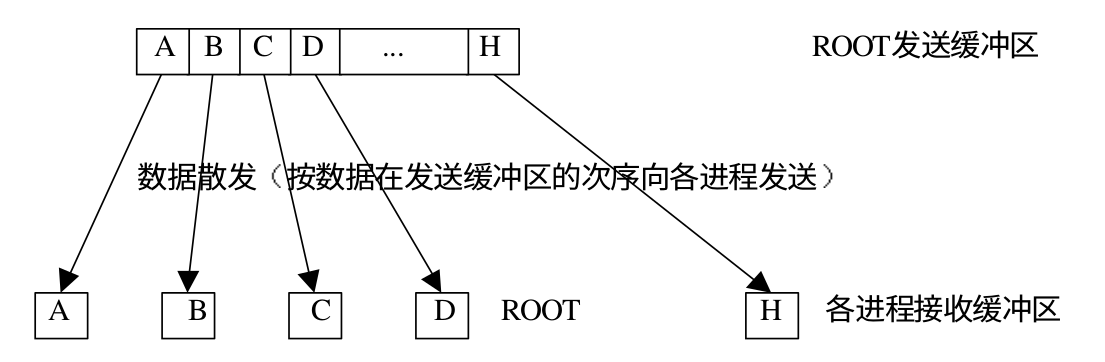
MPI_Scatterv 和 MPI_Gatherv 也是一对互逆操作,下面是 MPI_Scatterv 的函数原型
int MPI_scatter(
void * sendbuf, // 发送缓冲区的起始地址
int* sendcounts, // 向每个进程发送的数据个数
int* displs, // 发送数据的偏移
MPI_Datatype sendtype, // 发送数据类型
void * recvbuf, // 接收缓冲区的起始地址
int recvcount, // 接收数据的个数
MPI_Datatype recvtype, // 接收数据的类型
int root, // 根进程的编号
MPI_Comm comm // 通信域
);
下面是使用 MPI_Scatter 的一个示例:
void scatter() {
int size;
int rank;
int n = 10;
int * send_array;
int recv_array[n];
int i, j;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if(rank == 0) {
send_array = (int *)malloc(sizeof(int) * n * size);
for(i = 0; i < n * size; i++) {
send_array[i] = i;
}
}
MPI_Scatter(send_array, n, MPI_INT, recv_array, n, MPI_INT, 0, MPI_COMM_WORLD);
for(i = 0; i < size; i++) {
MPI_Barrier(MPI_COMM_WORLD);
if(rank == i) {
for(j = 0;j < n; j++) {
printf("Process %d recv[%d] is %d\n", rank, j, recv_array[j]);
}
}
}
MPI_Finalize();
}
组收集
MPI_Gather 是将数据收集到 root 进程,而 MPI_Allgather 相当于每个进程都作为 root 进程执行了一次 MPI_Gather 调用,即一个进程都收集到了其它所有进程的数据。下面是 MPI_Allgather 的函数原型:
int MPI_Allgather(
void * sendbuf, // 发送缓冲区的起始地址
int sendcount, // 向每个进程发送的数据个数
MPI_Datatype sendtype, // 发送数据类型
void * recvbuf, // 接收缓冲区的起始地址
int recvcount, // 接收数据的个数
MPI_Datatype recvtype, // 接收数据的类型
MPI_Comm comm // 通信域
);
下面是 MPI_Allgather 的示意图
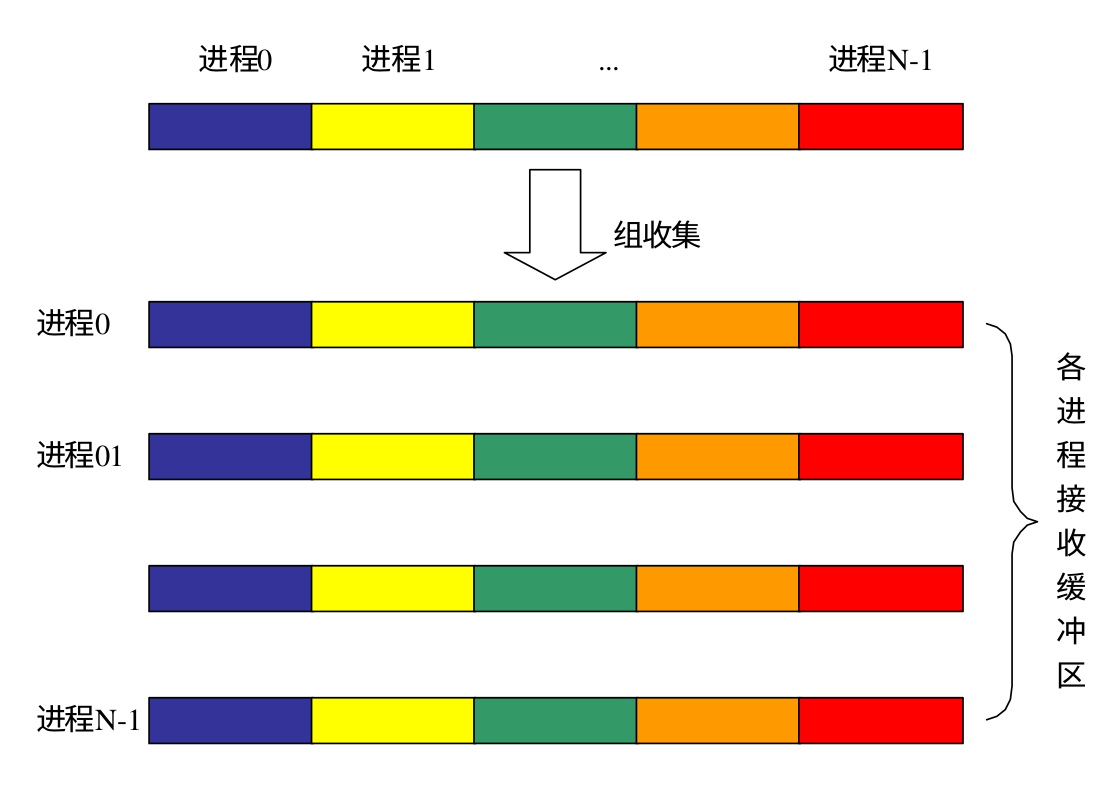
MPI_Allgatherv 和 MPI_Allgather 功能类似,只不过可以为每个进程指定发送和接受的数据个数以及接受缓冲区的起始地址,下面是 MPI_Allgatherv 的函数原型:
int MPI_Allgather(
void * sendbuf,
int sendcount,
MPI_Datatype sendtype,
void * recvbuf,
int* recvcounts,
int * displs,
MPI_Datatype recvtype,
MPI_Comm comm
);
全互换
MPI_Alltoall 是组内进程完全交换,每个进程都向其它所有的进程发送消息,同时每一个进程都从其他所有的进程接收消息。它与 MPI_Allgather 不同的是:MPI_Allgather 接收完消息后每个进程接收缓冲区的数据是完全相同的,但是 MPI_Alltoall 接受完消息后接收缓冲区的数据一般是不同的,下面是 MPI_Alltoall 的示意图,如果将进程和对应的数据看做是一个矩阵的话,MPI_Alltoall 就相当于把矩阵的行列置换了一下:
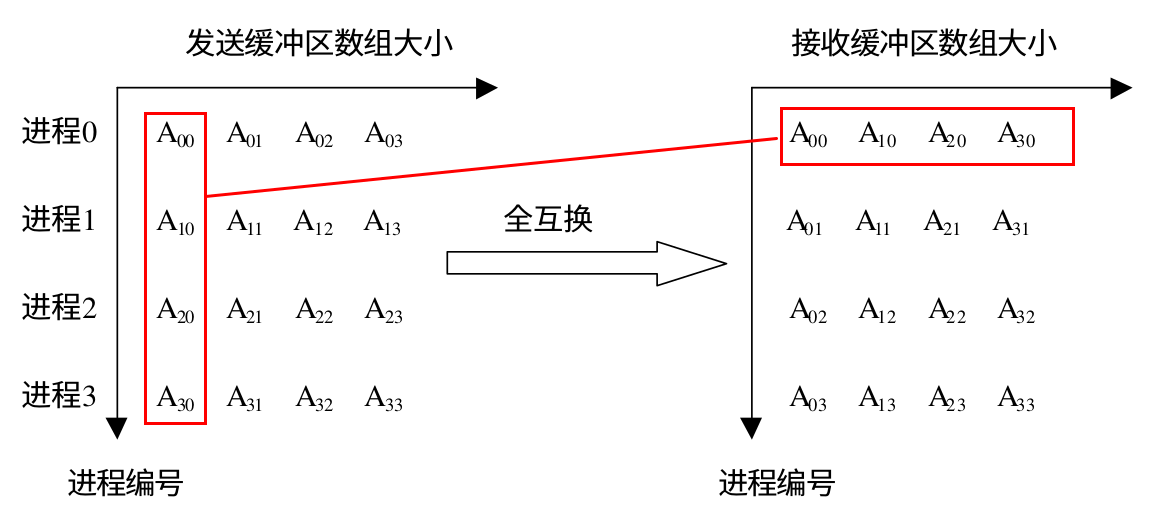
下面是 MPI_Alltoall 和 MPI_Alltoallv 的函数原型:
int MPI_Alltoall(
void * sendbuf,
int sendcount,
MPI_Datatype sendtype,
void * recvbuf,
int recvcount,
MPI_Datatype recvtype,
MPI_Comm comm
);
int MPI_Alltoallv(
void * sendbuf,
int sendcount,
MPI_Datatype sendtype,
void * recvbuf,
int* recvcounts,
int * displs,
MPI_Datatype recvtype,
MPI_Comm comm
);
下面是使用 MPI_Alltoall 的一个示例:
void all_to_all() {
int size;
int rank;
int n = 2;
int i;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int send_array[n * size];
int recv_array[n * size];
for(i = 0; i < n * size; i++) {
send_array[i] = (rank+1) * (i + 1);
}
MPI_Alltoall(send_array, n, MPI_INT, recv_array, n, MPI_INT, MPI_COMM_WORLD);
for(i = 0; i < size; i++) {
MPI_Barrier(MPI_COMM_WORLD);
if(rank == i) {
for(j = 0;j < n * size; j++) {
printf("Process %d recv[%d] is %d\n", rank, j, recv_array[j]);
}
}
}
MPI_Finalize();
}
进程同步
MPI_Barrier 会阻塞进程,直到组中的所有成员都调用了它,组中的进程才会往下执行,在上面的代码中我们使用 MPI_Barrier 来顺序输出每个进程的数据,
for(i = 0; i < size; i++) {
MPI_Barrier(MPI_COMM_WORLD);
if(rank == i) {
for(j = 0;j < n * size; j++) {
printf("Process %d recv[%d] is %d\n", rank, j, recv_array[j]);
}
}
}
这里解释一下为什么下面的代码可以做到顺序输出。我们直到 MPI_Barrier 的作用是阻塞进程,直到所有进程都到达这个点。当第一次循环时,各个进程在 MPI_Barrier 的地方首先同步一下,然后继续往下执行,进程 1, 2, 3 直接跳过开始第二次循环,而进程 0 开始输出自己的数据。而进程 1, 2, 3 又会在 MPI_Barrier 处等待,直到进程 0 输出完数据,也到达第二次循环的同步点。此时所有的进程又开始往下执行。不过和上次不同的是,这次是进程 0, 2, 3 进入第三次循环,而进程 1 开始输出数据。进程 0, 2, 3 又会在 MPI_Barrier 处等待进程 1 。重复上面的过程,我们就可以顺序输出每个进程的数据。
下面是 MPI_Barrier 的函数原型:
int MPI_Barrier(
MPI_Comm comm
);
计算
规约
MPI_Reduce 用来将组内每个进程输入缓冲区中的数据按给定的操作 op 进行预案算,然后将结果返回到序号为 root 的接收缓冲区中。操作 op 始终被认为是可以结合的,并且所有 MPI 定义的操作被认为是可交换的。用户自定义的操作被认为是可结合的,但是可以不是可交换的(先抄下来,不太懂)。下面是 MPI_Reduce 的示意图:
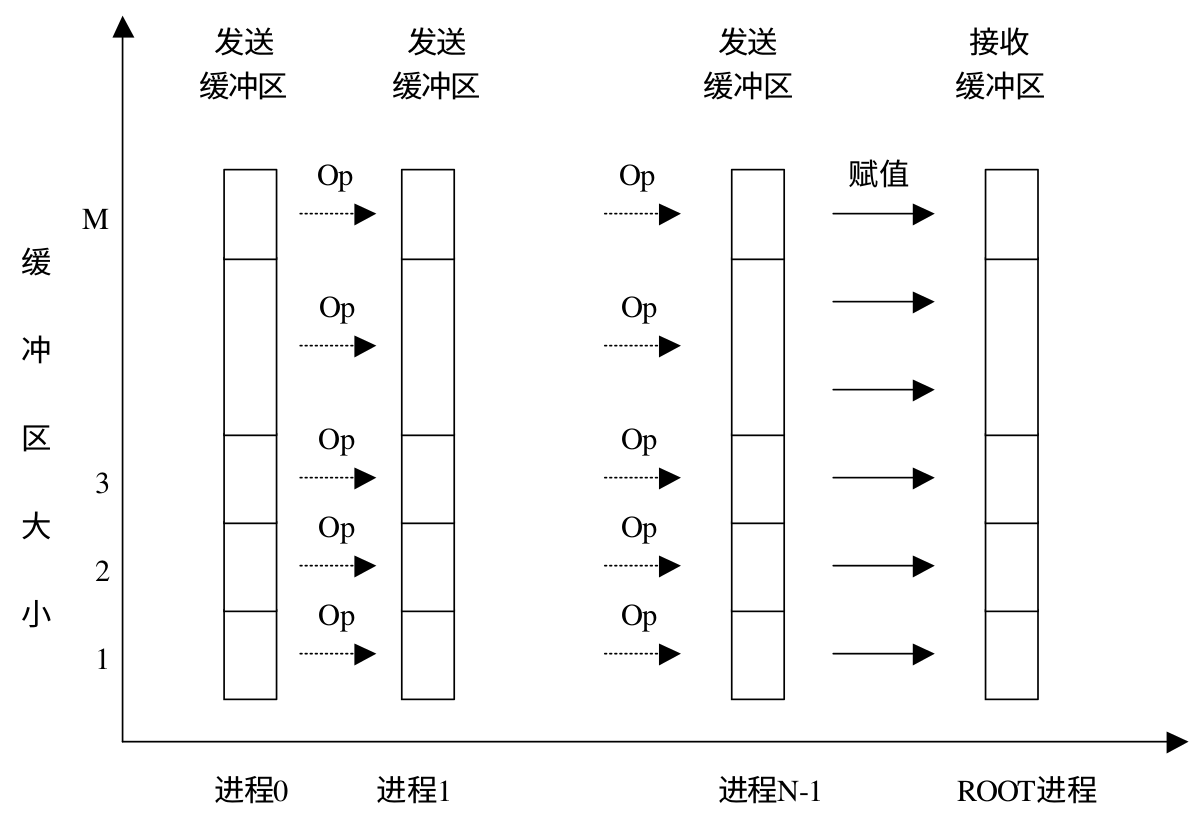
下面是 MPI_Reduce 的函数原型
int MPI_Reduce(
void * sendbuf, // 发送缓冲区的起始地址
void * recvbuf, // 接收缓冲区的起始地址
int count, // 发送/接收 消息的个数
MPI_Datatype datatype, // 发送消息的数据类型
MPI_Op op, // 规约操作符
int root, // 根进程序列号
MPI_Comm comm // 通信域
);
MPI 预定义了一些规约操作,如下表所示:
| 操作 | 含义 |
|---|---|
| MPI_MAX | 最大值 |
| MPI_MIN | 最小值 |
| MPI_SUM | 求和 |
| MPI_PROD | 求积 |
| MPI_LAND | 逻辑与 |
| MPI_BAND | 按位与 |
| MPI_LOR | 逻辑或 |
| MPI_BOR | 按位或 |
| MPI_LXOR | 逻辑异或 |
| MPI_BXOR | 按位异或 |
| MPI_MAXLOC | 最大值且相应位置 |
| MPI_MINLOC | 最小值且相应位置 |
下面是使用 MPI_Reduce 的一个示例:
void reduce() {
int size;
int rank;
int n = 2;
int send_array[n];
int recv_array[n];
int i, j;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
for(i = 0; i < n ; i++) {
send_array[i] = i + n * (rank + 1);
}
MPI_Reduce(send_array, recv_array, n, MPI_INT,MPI_SUM, 0, MPI_COMM_WORLD);
if(rank == 0) {
for(j = 0;j < n; j++) {
printf("Process %d recv[%d] is %d\n", rank, j, recv_array[j]);
}
}
MPI_Finalize();
}
计算 PI
PI 的计算公式可以通过下面的公式计算出来:
使用 MPI 并行的思路是每个进程计算一部分 N 值,计算完成之后通过 MPI_Reduce 将结果收集起来,下面是实现代码:
void cal_pi_mpi() {
int N = 10;
int size = 0;
int rank = 0;
int start;
int end;
int unit_space = 0;
int i;
double pi = 0.0;
double result;
double x;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
unit_space = N / size;
if(rank == size - 1) {
start = unit_space * rank;
end = N;
} else {
start = unit_space * rank;
end = unit_space * (rank + 1);
}
for(i = start + 1; i <= end; i++) {
x = (i - 0.5) / N;
pi += fx(x);
}
MPI_Reduce(&pi, &result, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if(rank == 0) {
result /= N;
printf("result is %.16f\n", result);
}
MPI_Finalize();
}
组规约
组规约 MPI_Allreduce 相当于组中每个进程作为 ROOT 进行了一次规约操作,即每个进程都有规约的结果。下面是 MPI_Allreduce 的函数原型
int MPI_Reduce(
void * sendbuf, // 发送缓冲区的起始地址
void * recvbuf, // 接收缓冲区的起始地址
int count, // 发送/接收 消息的个数
MPI_Datatype datatype, // 发送消息的数据类型
MPI_Op op, // 规约操作符
MPI_Comm comm // 通信域
);
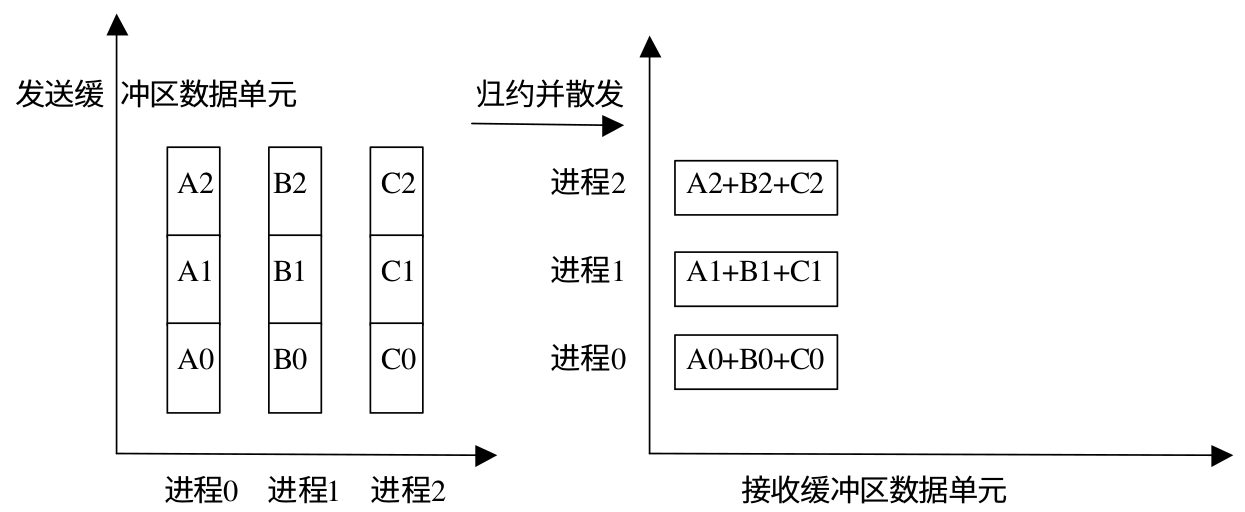
规约并散发
MPI_Reduce_scatter 会将规约结果分散到组内的所有进程中去。在 MPI_Reduce_scatter 中,发送数据的长度要大于接收数据的长度,这样才可以把规约的一部分结果散射到各个进程中。该函数的参数中有个 recvcounts 数组,用来记录每个进程结束数据的数量,这个数组元素的和就是发送数据的长度。下面是示意图
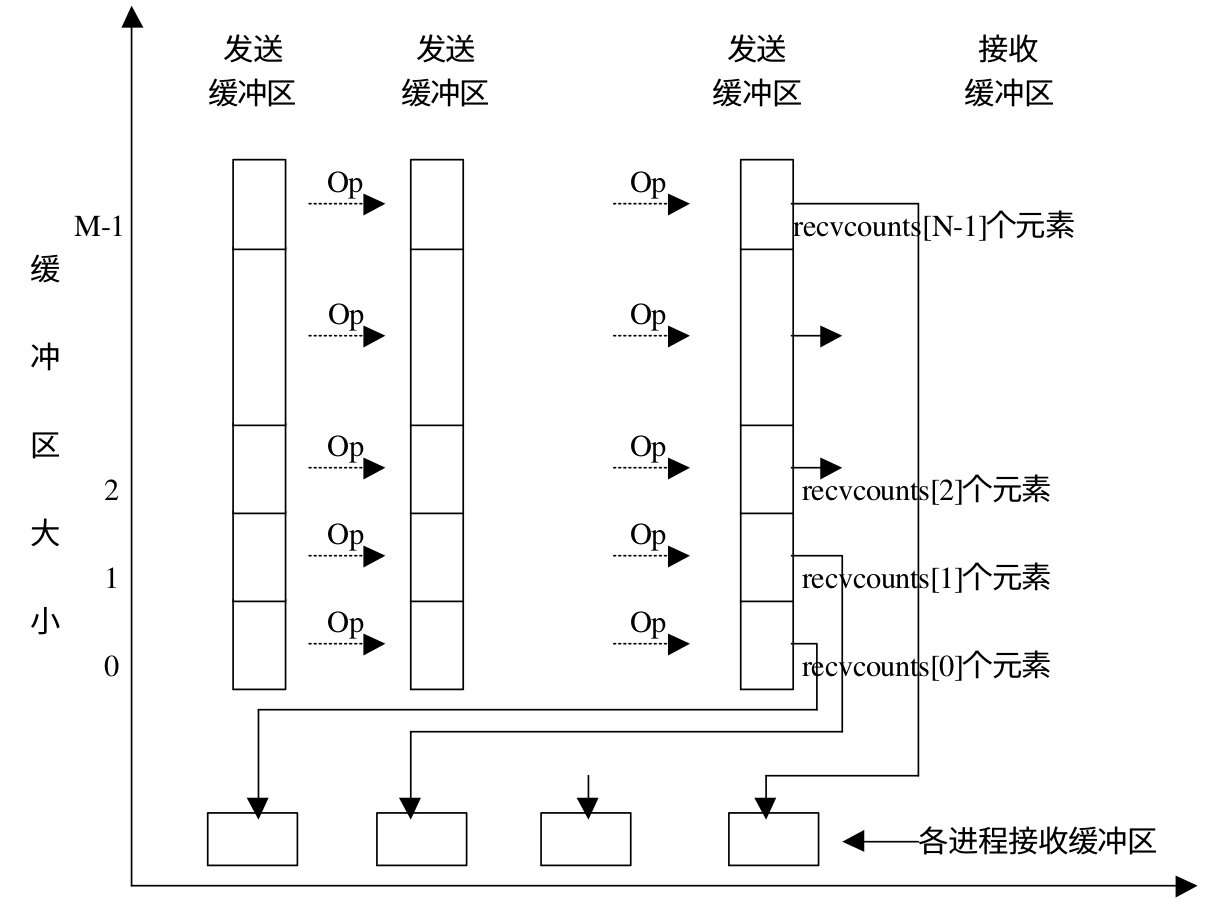
下面是函数原型:
int MPI_Reduce(
void * sendbuf, // 发送缓冲区的起始地址
void * recvbuf, // 接收缓冲区的起始地址
int* recvcounts, // 接受数据的个数(数组)
MPI_Datatype datatype, // 发送消息的数据类型
MPI_Op op, // 规约操作符
MPI_Comm comm // 通信域
);
下面是一个使用示例:
void reduce_gather() {
int size;
int rank;
int n = 2;
int i, j;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int send_array[n];
int recv_array[n];
int num[size];
for(i = 0; i < size; i++) {
num[i] = n;
}
for(i = 0; i < n* size ; i++) {
send_array[i] = i + n * (rank + 1);
}
MPI_Reduce_scatter(send_array, recv_array, num, MPI_INT,MPI_SUM, MPI_COMM_WORLD);
for(i = 0; i < size; i++) {
MPI_Barrier(MPI_COMM_WORLD);
if(rank == i) {
for(j = 0;j < n; j++) {
printf("Process %d recv[%d] is %d\n", rank, j, recv_array[j]);
}
}
}
}
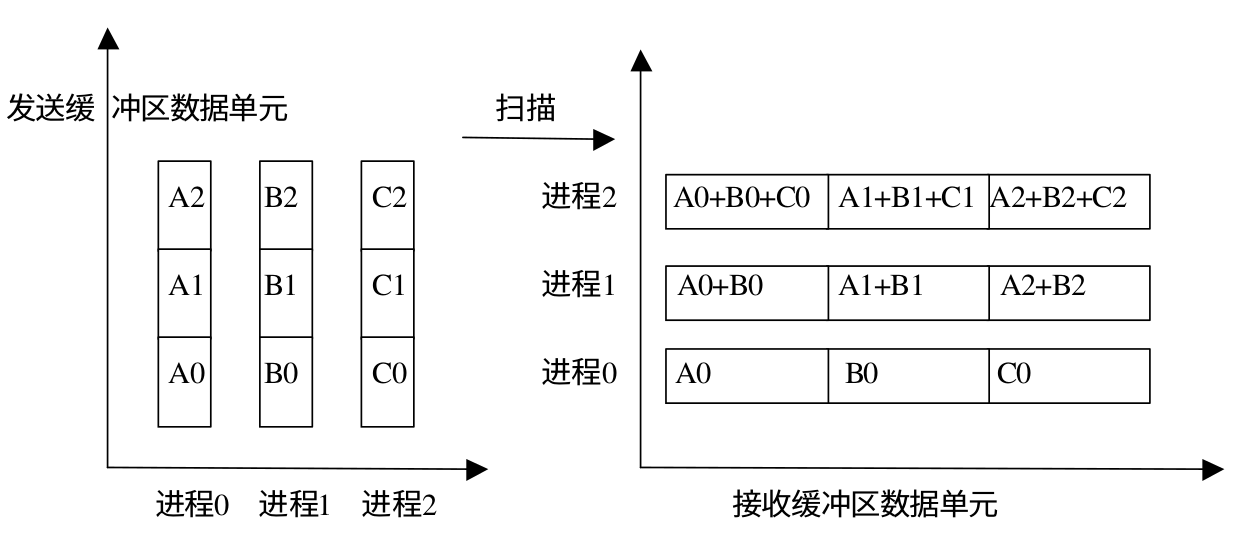
扫描
可以将扫面看做是一种特殊的规约,即每个进程都对排在它前面的进程进行规约操作。 MPI_Scan 的调用结果是,对于每一个进程i,它对进程 0,...,1 的发送缓冲区的数据进行指定的规约操作,结果存入进程 i 的接收缓冲区。下面是 MPI_Scan 的函数原型:
int MPI_Reduce(
void * sendbuf, // 发送缓冲区的起始地址
void * recvbuf, // 接收缓冲区的起始地址
int count, // 输入缓冲区中元素的个数
MPI_Datatype datatype, // 发送消息的数据类型
MPI_Op op, // 规约操作符
MPI_Comm comm // 通信域
);
规约操作对比
下面是不同的规约操作的数据变化:
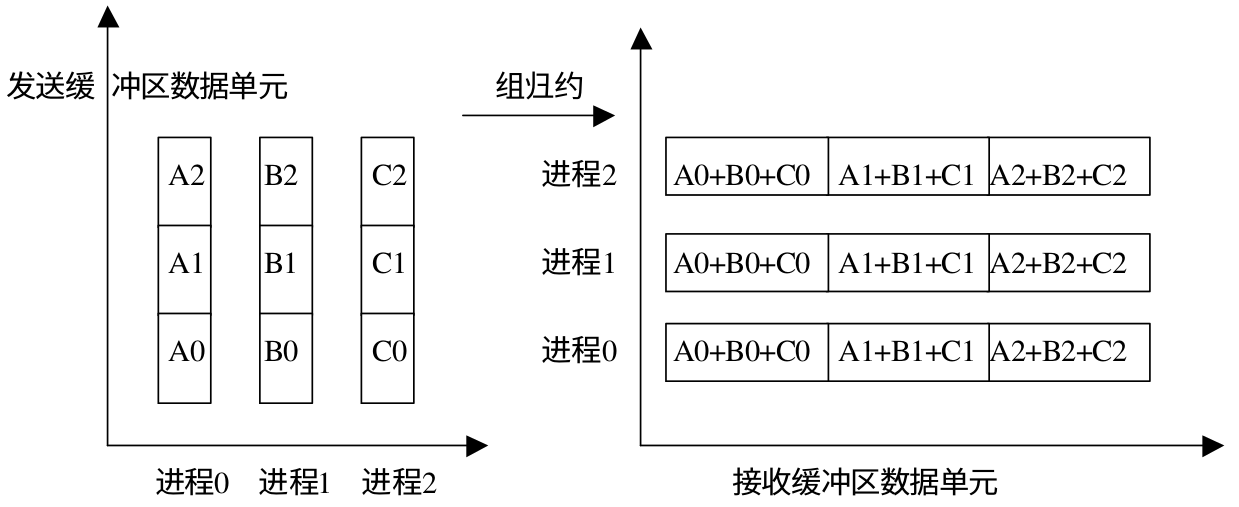
规约操作:
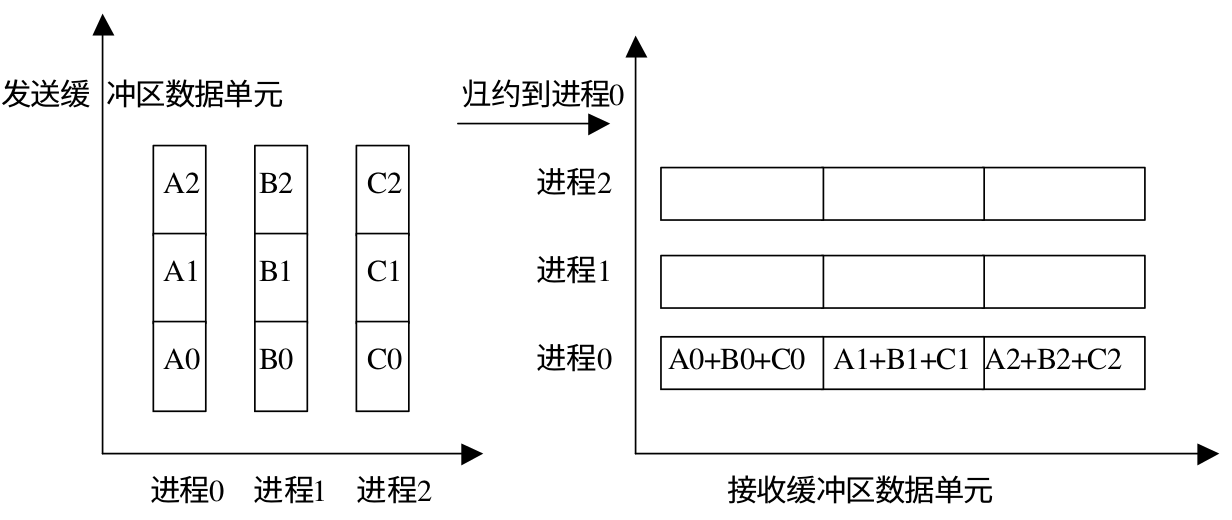
组规约操作:
规约并发散操作
扫描操作
最大值与最小值
MPI_MINLOC 用来计算全局最小值和最小值所在进程的索引,MPI_MAXLOC 用来计算全局最大值和最大值的索引。这里我们可以看到得到的结果是值和索引,所以需要定义一个 struct 来存储这两个值,下面是一个示例:
struct {
int value;
int rank;
} in[n], out[n];
rank的类型一定是整形,但是 value 的值可以不是整形,因此在 MPI 里定义几种类型用来指定 value 是什么类型的值,如下所示:
| 名称 | 描述 |
|---|---|
| MPI_FLOAT_INT | 浮点型和整形 |
| MPI_DOUBLE_INT | 双精度和整形 |
| MPI_LONG_INT | 长整形和整形 |
| MPI_2INT | 整型值对 |
| MPI_SHORT_INT | 短整形和整形 |
| MPI_LONG_DOUBLE_INT | 长双精度浮点型和整型 |
下面是一个使用示例:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "mpi.h"
void max() {
int n = 10;
int max_value = 100;
struct {
int value;
int rank;
} in[n], out[n];
int rank;
int size;
int i, j;
MPI_Init(NULL, NULL);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
srand(time(NULL) + rank);
for(i = 0; i < n; i++) {
in[i].value = rand() % max_value;
in[i].rank = rank;
}
for(j = 0; j < size; j++) {
MPI_Barrier(MPI_COMM_WORLD);
if(j == rank) {
for(i = 0; i < n; i++) {
printf("thread %d in[%d] is %d\n", j, i, in[i].value);
}
}
}
MPI_Reduce(in, out, n, MPI_2INT, MPI_MAXLOC, 0, MPI_COMM_WORLD);
if(rank == 0) {
for(i = 0; i < n; i++) {
printf("max[%d] in thread %d and value is %d\n", i, out[i].rank, out[i].value);
}
}
MPI_Finalize();
}
int main() {
max();
}
自定义规约操作
我们可以通过调用 MPI_Op_create 来自定义规约操作,下面是函数原型:
int MPI_Op_create(
MPI_User_function * function, // 用户自定义函数
int commute, // 是否可交换,是true,否false
MPI_Op *op // 操作句柄
)
这里需要注意的是用户自定义的操作必须是可以结合的,即 a+b+c = a+(b+c),像减法都不满足结合率,a-b-c ≠ a-(b-c),如果commute=ture,那么操作同时也是可交换的。function 是用户自定义的函数,函数必须具备四个参数,原型如下所示:
void user_function_name(
void * invec, // 被规约元素 1 所在缓冲区的首地址
void * inoutvec, // 被规约元素 2 所在缓冲区的首地址,返回结果要保存到这个数组里
int * len, // 数组长度
MPI_Datatype * datatype // 数据类型
)
使用 MPI_Op_free 可以释放掉规约操作,下面是函数原型:
int MPI_Op_free(MPI_Op *op)
下面是一个减法的示例,上面我们说了减法不满足结合率,所以结果和预期的是不一样的,不过我们可以从下面的示例看到如何自定义操作
#include <stdio.h>
#include <stdlib.h>
#include "mpi.h"
void my_prod(void * in, void * inout, int *len, MPI_Datatype *datatype) {
int * in_tmp = (int *)in;
int * inout_tmp = (int *)inout;
int i;
for(i = 0; i < *len; i++) {
printf("in_tmp is %d and inout_tmp is %d\n", *in_tmp, *inout_tmp);
*inout_tmp = *in_tmp - *inout_tmp;
in_tmp++;
inout_tmp++;
}
}
void op() {
int n = 10;
int in[n], out[n];
int rank;
int size;
int i, j;
MPI_Op my_op;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
for(i = 0; i < n; i++) {
in[i] = i * rank;
}
for(j = 0; j < size; j++) {
MPI_Barrier(MPI_COMM_WORLD);
if(j == rank) {
for(i = 0; i < n; i++) {
printf("thread %d in[%d] is %d\n", j, i, in[i]);
}
}
}
MPI_Op_create(my_prod, 0 , &my_op);
MPI_Reduce(in, out, n, MPI_INT, my_op, 0, MPI_COMM_WORLD);
if(rank == 0) {
for(i = 0; i < n; i++) {
printf("out[%d] is %d\n", i, out[i]);
}
}
MPI_Finalize();
}
int main() {
op();
}